Test Configuration
Hardware
- Platform
- NVIDIA Jetson Orin Nano 8GB Super
- GPU
- Ampere, 1024 CUDA / 32 Tensor cores
- Memory
- 8GB unified LPDDR5, 68 GB/s
- JetPack
- 6.2 (R36.4.7)
- TensorRT
- 10.3.0
- CUDA
- 12.6
Test Parameters
- Engine
- prithvi_fp16.trt (620 MB)
- Input shape
- (1, 6, 4, 224, 224)
- Tiles per run
- 400
- Warmup tiles
- 10
- Cooldown
- 120s between modes
- Clock governor
- Dynamic (default)
Sustained Throughput
| Power Mode | Throughput | p50 | p95 | p99 | 100 tiles | 400 tiles |
|---|---|---|---|---|---|---|
| 7W | 3.6 tiles/s | 273 ms | 273 ms | 273 ms | 27s | 110s |
| 15W | 9.7 tiles/s | 102 ms | 102 ms | 102 ms | 10s | 41s |
| 25W | 14.4 tiles/s | 68 ms | 68 ms | 69 ms | 7s | 28s |
| MAXN | 14.3 tiles/s | 69 ms | 69 ms | 70 ms | 7s | 28s |
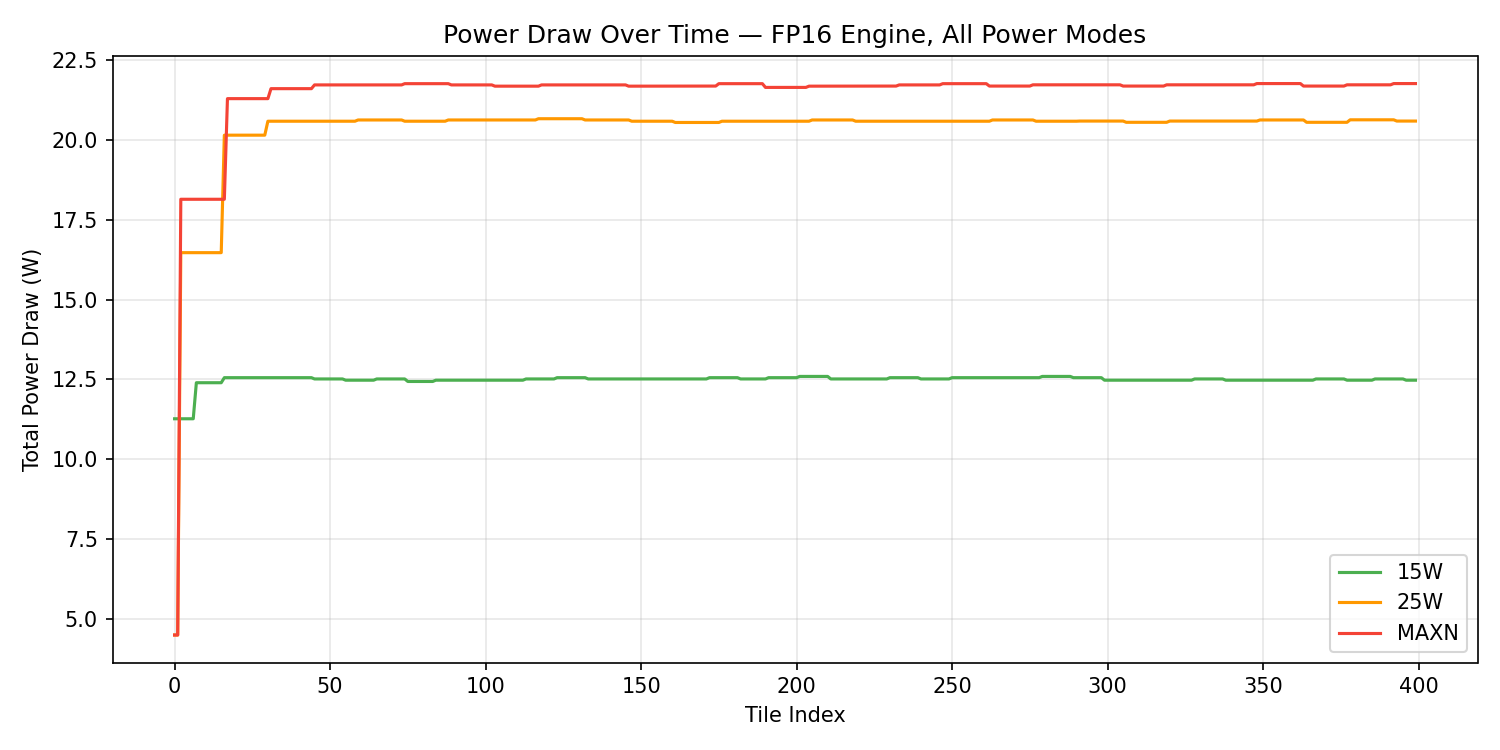
Power Efficiency
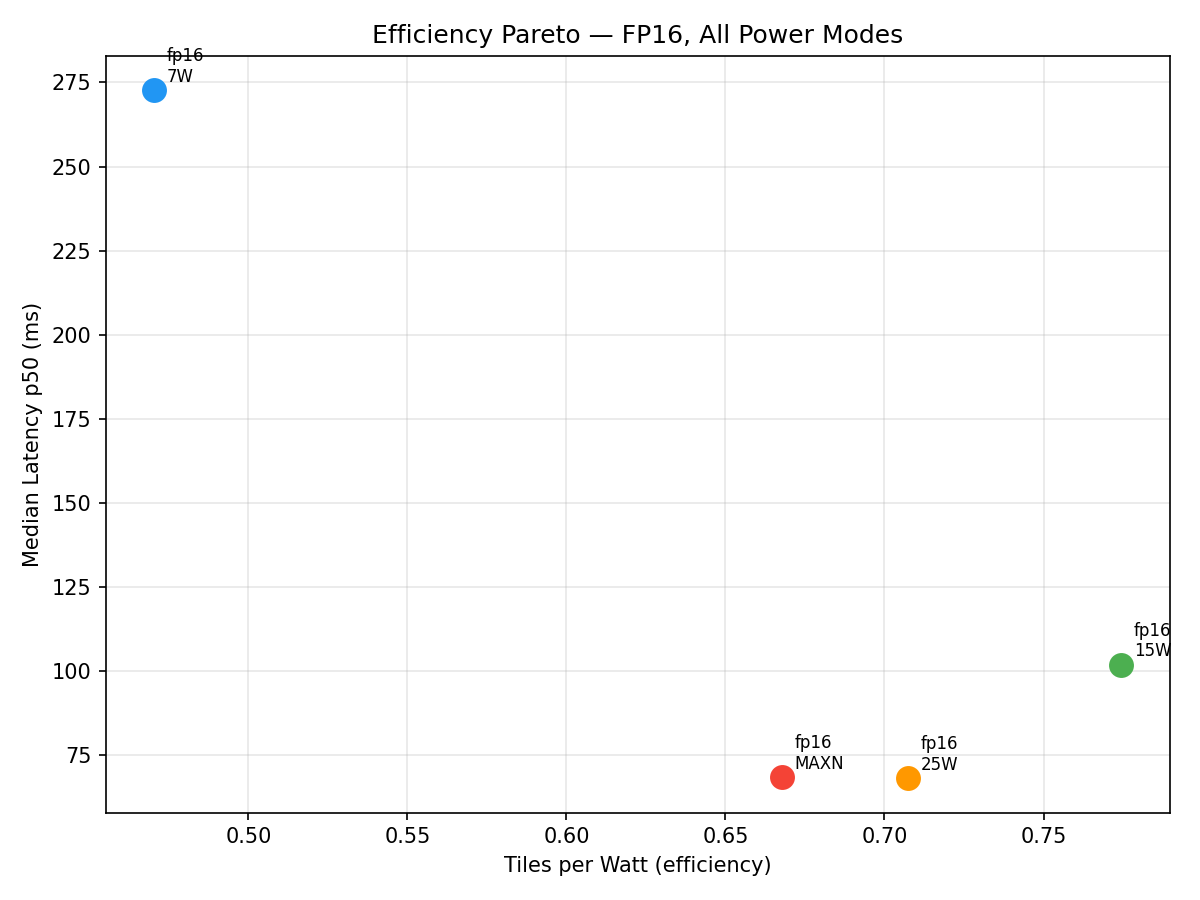
| Mode | Mean W | J / tile | Tiles / W |
|---|---|---|---|
| 7W | 7.8W | 2.13 | 0.47 |
| 15W | 12.5W | 1.29 | 0.77 |
| 25W | 20.3W | 1.41 | 0.71 |
| MAXN | 21.5W | 1.50 | 0.67 |
Key Finding
15W is the energy-optimal mode at 1.29 J/tile. 25W provides best raw throughput but MAXN offers no benefit over 25W — wasted power for identical performance.
Thermal Behavior
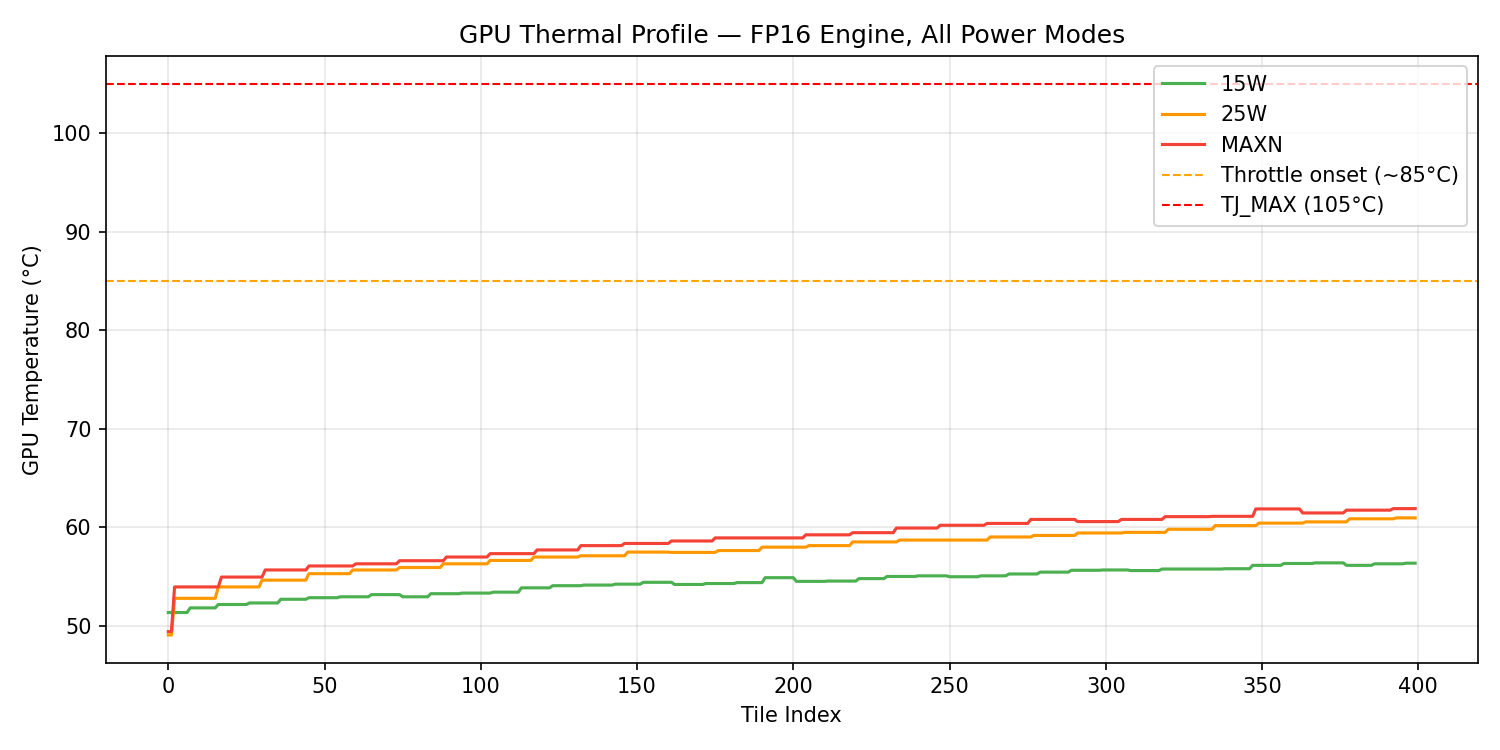
7W
Peak: 53.1°C
52°C to TJ_MAX
15W
Peak: 56.4°C
49°C to TJ_MAX
25W
Peak: 61.0°C
44°C to TJ_MAX
MAXN
Peak: 61.9°C
43°C to TJ_MAX
TJ_MAX = 105°C (thermal shutdown). All modes operate with >40°C thermal headroom. Zero swap activity across all runs.
Latency Stability
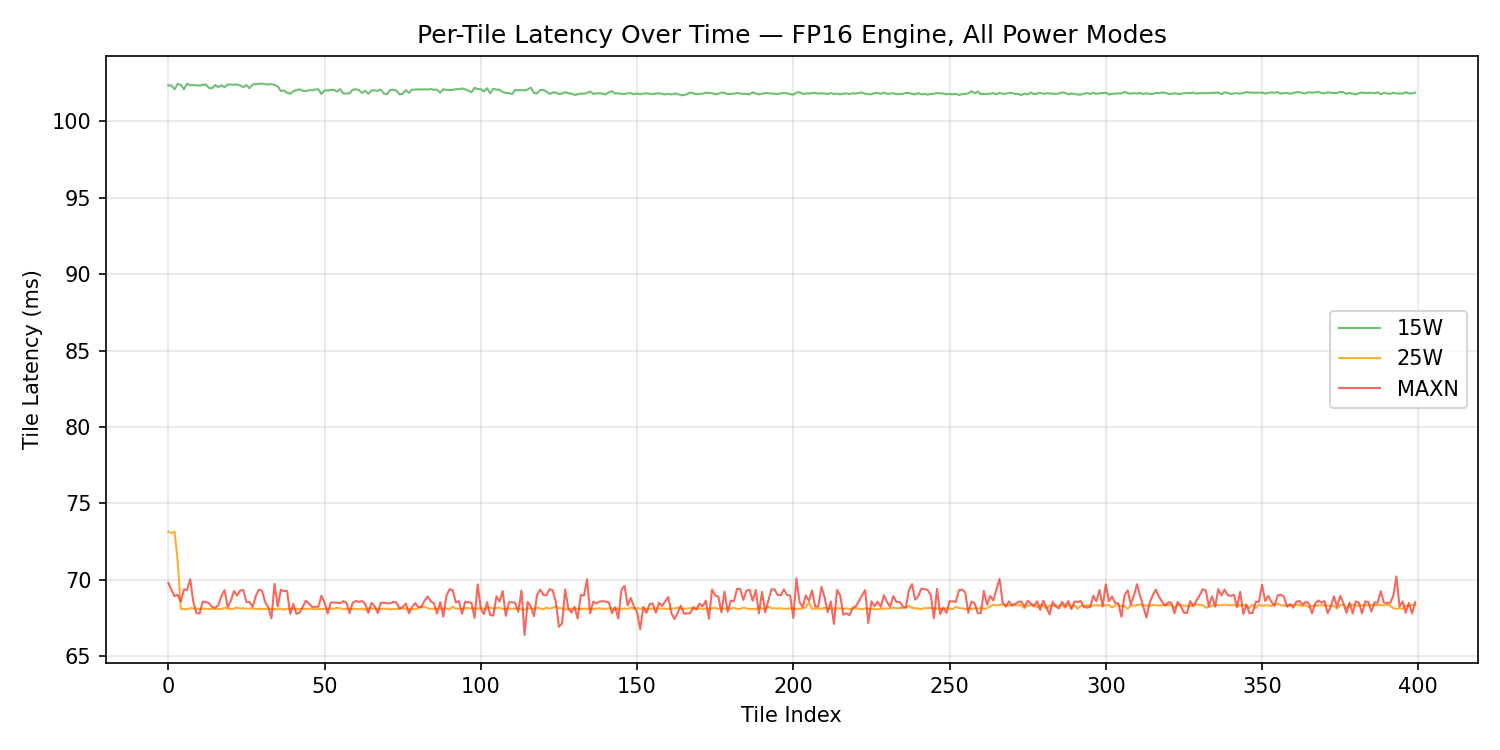
| Power Mode | First 10 tiles (p50) | Last 10 tiles (p50) | Degradation |
|---|---|---|---|
| 7W | 272.61 ms | 272.63 ms | +0.01% |
| 15W | 102.36 ms | 101.83 ms | -0.52% |
| 25W | 68.13 ms | 68.31 ms | +0.25% |
| MAXN | 69.17 ms | 68.49 ms | -0.98% |
Scene Processing Estimates
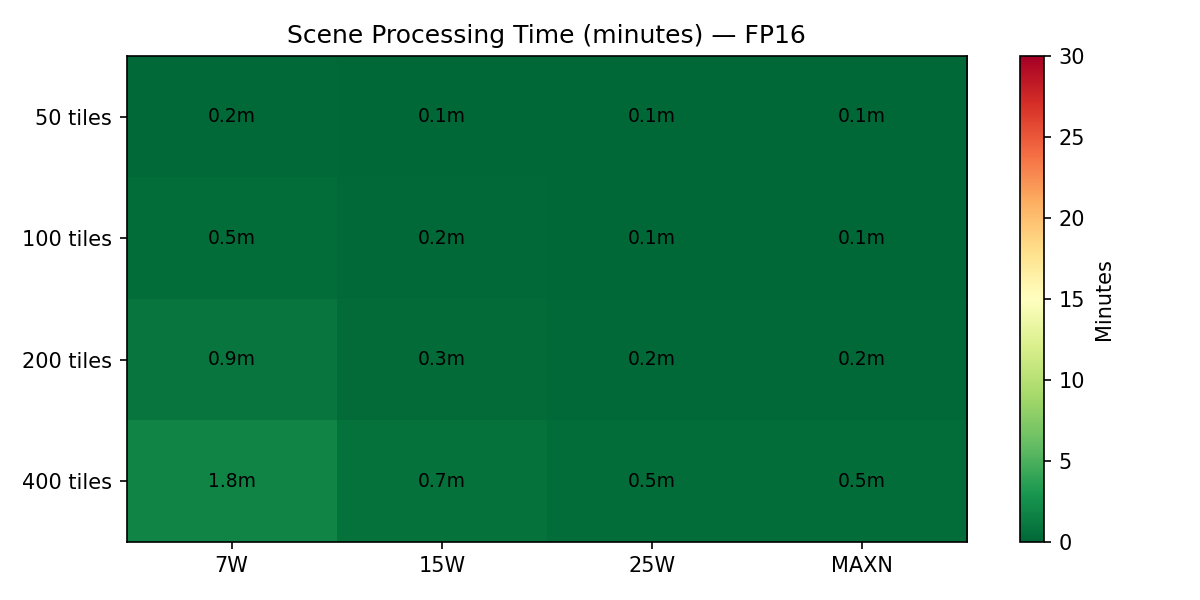
7W
1 min 50s
Ultra-low power
15W
41s
Energy optimal
25W
28s
Latency optimal
MAXN
28s
No benefit over 25W
Precision Constraints
FP16 Accuracy Validation
- MAE
- 4.55e-02 (threshold < 5e-02) — PASS
- Cosine Similarity
- 0.9948 (threshold > 0.99) — PASS
- Method
- 20 tiles, PyTorch FP32 CPU ground truth
- Verdict
- Functionally identical to FP32
INT8 Memory Ceiling
INT8 engine compilation for Prithvi-300M requires >578 MB contiguous GPU memory for block 23 fused constants. On the 8GB Orin Nano, this exceeds available memory after blocks 0-22 are compiled.
Tested exhaustively: native Python, Docker, trtexec CLI, opt_level 0-3, workspace 256-512 MB. All fail at the same point. This is a physical memory limitation, not a configuration issue.
INT8 deployment targets Jetson AGX Orin 64GB (275 TOPS, 204 GB/s bandwidth). Expected INT8 p50: ~10-15 ms.
Recommendations
Energy-Constrained
FP16 @ 15W
1.29 J/tile · 9.7 tiles/s · 0.77 tiles/W
Maximizes mission endurance on limited solar/battery budget. 400-tile scene in 41 seconds.
Latency-Constrained
FP16 @ 25W
68 ms p50 · 14.4 tiles/s · 0.71 tiles/W
Minimizes per-tile latency for time-critical detection. 400-tile scene in 28 seconds.